Proc Freq Table Riskdiff How to Read
The post-obit statements are available in PROC FREQ.
-
PROC FREQ < options > ;
-
BY variables ;
-
EXACT statistic-options < / computation-options > ;
-
OUTPUT < OUT= SAS-data-set > options ;
-
TABLES requests < / options > ;
-
Test options ;
-
WEIGHT variable < / option > ;
-
The PROC FREQ statement is the merely required statement for the FREQ procedure. If you specify the post-obit statements, PROC FREQ produces a ane-manner frequency table for each variable in the almost recently created data set.
The residual of this section gives detailed syntax information for the By, Exact, OUTPUT, TABLES, Test, and WEIGHT statements in alphabetical order afterward the description of the PROC FREQ argument. Table 2.3 summarizes the basic functions of each statement.
| Argument | Description |
|---|---|
| BY | calculates separate frequency or crosstabulation tables for each By group . |
| Verbal | requests exact tests for specified statistics. |
| OUTPUT | creates an output data prepare that contains specified statistics. |
| TABLES | specifies frequency or crosstabulation tables and requests tests and measures of association. |
| Test | requests asymptotic tests for measures of association and agreement. |
| WEIGHT | identifies a variable with values that weight each observation. |
PROC FREQ Statement
-
PROC FREQ < options > ;
The PROC FREQ statement invokes the procedure.
The post-obit table lists the options available in the PROC FREQ statement. Descriptions follow in alphabetical order.
| Option | Description |
|---|---|
| Information= | specifies the input data set. |
| Compress | begins the next one-way table on the current folio |
| FORMCHAR= | specifies the outline and cell divider characters for the cells of the crosstabulation table. |
| NLEVELS | displays the number of levels for all TABLES variables |
| NOPRINT | suppresses all displayed output. |
| Gild= | specifies the social club for list variable values. |
| Folio | displays one table per page. |
You tin can specify the following options in the PROC FREQ argument.
Compress
-
begins brandish of the adjacent one-mode frequency table on the same page every bit the preceding one-fashion table if there is enough space to begin the tabular array. By default, the next ane-way table begins on the current page only if the entire table fits on that page. The COMPRESS option is non valid with the PAGE selection.
Information= SAS-information-set
-
names the SAS data set to exist analyzed by PROC FREQ. If you omit the DATA= option, the procedure uses the about recently created SAS data set.
FORMCHAR (ane,2,7) = formchar-string
-
defines the characters to be used for amalgam the outlines and dividers for the cells of contingency tables. The FORMCHAR= option can specify 20 different SAS formatting characters used to display output; however, PROC FREQ uses just the start, second, and seventh formatting characters. Therefore, the proper specification for PROC FREQ is FORMCHAR(1,2,vii)= formchar-string . The formchar-cord should be three characters long. The characters are used to announce (1) vertical separator, (2) horizontal separator, and (seven) vertical-horizontal intersection. You tin can use any character in formchar-string , including hexadecimal characters. If you employ hexadecimal characters, you must put an ten after the closing quote. For information on which hexadecimal codes to apply for which characters, consult the documentation for your hardware.
-
Specifying all blanks for formchar-string produces tables with no outlines or dividers:
-
If you lot practice not specify the FORMCHAR= choice, PROC FREQ uses the default
-
Refer to the CALENDAR, PLOT, and TABULATE procedures in the Base SAS 9.1 Procedures Guide for more information on grade characters.
Tabular array 2.5: Formatting Characters Used by PROC FREQ Position
Default
Used to Draw
ane
vertical separators
2
-
horizontal separators
7
+
intersections of vertical and horizontal separators
NLEVELS
-
displays the Number of Variable Levels table. This table provides the number of levels for each variable named in the TABLES statements. Run across the section Number of Variable Levels Table on page 151 for more information. PROC FREQ determines the variable levels from the formatted variable values, as described in the department Grouping with Formats on page 99.
NOPRINT
-
suppresses the display of all output. Note that this option temporarily disables the Output Delivery Organization (ODS). For more data, meet Chapter 14, Using the Output Delivery System. ( SAS/STAT User s Guide ).
Note: A NOPRINT option is likewise available in the TABLES statement. Information technology suppresses brandish of the crosstabulation tables but allows brandish of the requested statistics.
ORDER=Data FORMATTED FREQ INTERNAL
-
specifies the society in which the values of the frequency and crosstabulation table variables are to be reported . The following table shows how PROC FREQ interprets values of the ORDER= pick.
Information
orders values co-ordinate to their club in the input data set.
FORMATTED
orders values by their formatted values. This order is operating-environment dependent. By default, the order is ascending .
FREQ
orders values by descending frequency count.
INTERNAL
orders values by their unformatted values, which yields the same order that the SORT process does. This order is operating-environment dependent.
By default, ORDER=INTERNAL. The Gild= pick does not utilize to missing values, which are always ordered first.
PAGE
-
displays merely one table per folio. Otherwise , PROC FREQ displays multiple tables per page as space permits . The Folio selection is not valid with the Shrink option.
By Statement
-
Past variables ;
Yous tin specify a By argument with PROC FREQ to obtain divide analyses on observations in groups divers by the BY variables. When a BY statement appears, the process expects the input data set to exist sorted in order of the BY variables.
If your input data set is not sorted in ascending club, utilize one of the following alternatives:
-
Sort the information using the SORT procedure with a like BY statement.
-
Specify the BY statement option NOTSORTED or DESCENDING in the Past statement for the FREQ process. The NOTSORTED option does not hateful that the data are unsorted but rather that the data are arranged in groups (according to values of the Past variables) and that these groups are not necessarily in alphabetical or increasing numeric order.
-
Create an index on the By variables using the DATASETS procedure.
For more information on the Past argument, refer to the word in SAS Language Reference: Concepts . For more information on the DATASETS process, refer to the discussion in the Base SAS 9.i Procedures Guide .
EXACT Statement
-
Verbal statistic-options < / computation-options > ;
The Exact statement requests exact tests or conviction limits for the specified statistics. Optionally, PROC FREQ computes Monte Carlo estimates of the exact p -values. The statistic-options specify the statistics for which to provide exact tests or conviction limits. The computation-options specify options for the computation of exact statistics.
Caution: PROC FREQ computes exact tests with fast and efficient algorithms that are superior to straight enumeration. Exact tests are appropriate when a data set up is small, sparse, skewed, or heavily tied. For some large problems, ciphering of exact tests may crave a large amount of time and memory. Consider using asymptotic tests for such problems. Alternatively, when asymptotic methods may not be sufficient for such large problems, consider using Monte Carlo estimation of exact p -values. See the section Computational Resources on page 145 for more information.
Statistic-Options
The statistic-options specify the statistics for which exact tests or confidence limits are computed. PROC FREQ can compute exact p -values for the following hypothesis tests: chi-square goodness-of-fit test for one-style tables; Pearson chi-square, likelihood -ratio chi-foursquare, Mantel-Haenszel chi-square, Fisher due south exact examination, Jonckheere-Terpstra exam, Cochran-Armitage examination for trend, and McNemar s test for 2-way tables. PROC FREQ can also compute verbal p -values for tests of the following statistics: Pearson correlation coefficient, Spearman correlation coefficient, simple kappa coefficient, weighted kappa coefficient, and common odds ratio. PROC FREQ tin compute verbal p -values for the binomial proportion test for one-way tables, as well as verbal confidence limits for the binomial proportion. Additionally, PROC FREQ can compute verbal confidence limits for the odds ratio for 2 — 2 tables, as well as exact conviction limits for the mutual odds ratio for stratified 2 — two tables.
Table 2.6 lists the bachelor statistic-options and the exact statistics computed. Almost of the option names are identical to the corresponding options in the TABLES statement and the OUTPUT argument. You lot can request exact computations for groups of statistics by using options that are identical to the post-obit TABLES argument options: CHISQ, MEASURES, and Concord. For example, when you specify the CHISQ option in the Verbal argument, PROC FREQ computes exact p -values for the Pearson chi-foursquare, likelihood-ratio chi-square, and Mantel-Haenszel chi-square tests. You lot request exact p -values for an individual test by specifying one of the statistic-options shown in Table 2.6.
| Option | Exact Statistics Computed |
|---|---|
| Agree | McNemar s exam for two — 2 tables, simple kappa coefficient, and weighted kappa coefficient |
| BINOMIAL | binomial proportion test for ane-fashion tables |
| CHISQ | chi-square goodness-of-fit test for one-style tables; Pearson chi-foursquare, likelihood-ratio chi-square, and Mantel-Haenszel chi-square tests for 2-style tables |
| COMOR | confidence limits for the mutual odds ratio for h — 2 — 2 tables; common odds ratio examination |
| FISHER | Fisher s verbal examination |
| JT | Jonckheere-Terpstra examination |
| KAPPA | test for the simple kappa coefficient |
| LRCHI | likelihood-ratio chi-foursquare test |
| MCNEM | McNemar s test |
| MEASURES | tests for the Pearson correlation and the Spearman correlation, and the odds ratio confidence limits for 2 — 2 tables |
| MHCHI | Mantel-Haenszel chi-square test |
| OR | confidence limits for the odds ratio for ii — two tables |
| PCHI | Pearson chi-foursquare examination |
| PCORR | exam for the Pearson correlation coefficient |
| SCORR | exam for the Spearman correlation coefficient |
| TREND | Cochran-Armitage test for trend |
| WTKAP | exam for the weighted kappa coefficient |
Ciphering-Options
The computation-options specify options for computation of exact statistics. You can specify the following computation-options in the EXACT statement. ALPHA= ± specifies the level of the conviction limits for Monte Carlo p -value estimates. The value of the ALPHA= option must be betwixt 0 and 1, and the default is 0.01. A confidence level of ± produces 100(one ˆ' ± )% confidence limits. The default of Blastoff=.01 produces 99% conviction limits for the Monte Carlo estimates. The ALPHA= selection invokes the MC option.
MAXTIME= value
-
specifies the maximum clock time (in seconds) that PROC FREQ tin can use to compute an exact p -value. If the procedure does not complete the computation within the specified time, the computation terminates. The value of the MAXTIME= option must be a positive number. The MAXTIME= option is valid for Monte Carlo interpretation of exact p -values, equally well as for direct verbal p -value computation.
See the section Computational Resources on page 145 for more information.
MC
-
requests Monte Carlo interpretation of verbal p -values instead of directly exact p -value computation. Monte Carlo interpretation can be useful for big problems that crave a great amount of time and retention for exact computations but for which asymptotic approximations may non exist sufficient. Meet the department Monte Carlo Estimation on page 146 for more information.
The MC option is available for all Exact statistic-options except BINOMIAL, COMOR, MCNEM, and OR. PROC FREQ computes just exact tests or confidence limits for those statistics.
The Blastoff=, N=, and SEED= options likewise invoke the MC choice.
N= northward
-
specifies the number of samples for Monte Carlo estimation. The value of the N= option must be a positive integer, and the default is 10000 samples. Larger values of n produce more precise estimates of verbal p -values. Because larger values of n generate more samples, the computation time increases . The N= option invokes the MC option.
POINT
-
requests exact signal probabilities for the test statistics.
The Betoken option is available for all the EXACT argument statistic-options except the OR selection, which provides exact confidence limits as opposed to an exact test. The POINT option is not bachelor with the MC option.
SEED= number
-
specifies the initial seed for random number generation for Monte Carlo estimation. The value of the SEED= selection must be an integer. If you do not specify the SEED= pick, or if the SEED= value is negative or cipher, PROC FREQ uses the fourth dimension of twenty-four hour period from the computer s clock to obtain the initial seed. The SEED= option invokes the MC pick.
Using TABLES Statement Options with the Exact Statement
If you use only ane TABLES statement, you do not need to specify options in the TABLES statement that are identical to options appearing in the Verbal argument. PROC FREQ automatically invokes the corresponding TABLES statement option when you specify the option in the EXACT statement. However, when you apply multiple TABLES statements and want verbal computations, y'all must specify options in the TABLES statement to compute the desired statistics. PROC FREQ then performs exact computations for all statistics that are also specified in the EXACT statement.
OUTPUT Argument
-
OUTPUT < OUT= SAS-data-ready > options ;
The OUTPUT statement creates a SAS information set containing statistics computed by PROC FREQ. The variables comprise statistics for each ii-way table or stratum, too equally summary statistics beyond all strata.
Only i OUTPUT argument is allowed for each execution of PROC FREQ. You must specify a TABLES statement with the OUTPUT statement. If you use multiple TABLES statements, the contents of the OUTPUT data set stand for to the last TABLES statement. If you use multiple table requests in a TABLES statement, the contents of the OUTPUT information set correspond to the final table request.
For more than information, see the section Output Data Sets on page 148.
Note that yous can employ the Output Delivery System (ODS) to create a SAS information ready from any slice of PROC FREQ output. For more data, run into Table 2.11 on page 159 and Chapter 14, Using the Output Delivery System. ( SAS/STAT User southward Guide )
Yous tin specify the following options in an OUTPUT statement.
OUT= SAS-information-set
-
names the output information ready. If you omit the OUT= selection, the data set is named Information due north , where n is the smallest integer that makes the name unique.
options
-
specify the statistics that you want in the output information set. Available statistics are those produced by PROC FREQ for each one-mode or two-style table, likewise equally the summary statistics across all strata. When yous request a statistic, the OUTPUT data prepare contains that estimate or test statistic plus whatever associated standard error, confidence limits, p -values, and degrees of freedom. Yous can output statistics by using grouping options identical to those specified in the TABLES statement: Hold, ALL, CHISQ, CMH, and MEASURES. Alternatively, you can request an individual statistic past specifying ane of the options shown in the following table.
| Option | Output Data Set Statistics | Required TABLES Statement Pick |
|---|---|---|
| AGREE | McNemar s test for 2 — 2 tables, simple kappa coefficient, and weighted kappa coefficient; for square tables with more than than two response categories, Bowker southward test of symmetry; for multiple strata, overall simple and weighted kappa statistics, and tests for equal kappas among strata; for multiple strata with ii response categories, Cochran south Q test | AGREE |
| AJCHI | continuity-adjusted chi-foursquare for 2 — 2 tables | ALL or CHISQ |
| ALL | all statistics under CHISQ, MEASURES, and CMH, and the number of nonmissing subjects | ALL |
| BDCHI | Breslow-Solar day test | ALL or CMH or CMH1 or CMH2 |
| BIN BINOMIAL | for one-way tables, binomial proportion statistics | BINOMIAL |
| CHISQ | chi-square goodness-of-fit test for one-way tables; for ii-manner tables, Pearson chi-foursquare, likelihood-ratio chi-square, continuity-adjusted chi-square for ii — 2 tables, Mantel-Haenszel chi-square, Fisher due south exact test for 2 — two tables, phi coefficient, contingency coefficient, and Cramer s Five | ALL or CHISQ |
| CMH | Cochran-Mantel-Haenszel correlation, row mean scores (ANOVA), and general clan statistics; for 2 — two tables, logit and Mantel-Haenszel adapted odds ratios, relative risks, and Breslow-Solar day test | ALL or CMH |
| CMH1 | same as CMH, but excludes general association and row mean scores (ANOVA) statistics | ALL or CMH or CMH1 |
| CMH2 | same as CMH, but excludes the general association statistic | ALL or CMH or CMH2 |
| CMHCOR | Cochran-Mantel-Haenszel correlation statistic | ALL or CMH or CMH1 or CMH2 |
| CMHGA | Cochran-Mantel-Haenszel general association statistic | ALL or CMH |
| CMHRMS | Cochran-Mantel-Haenszel row hateful scores (ANOVA) statistic | ALL or CMH or CMH2 |
| COCHQ | Cochran s Q | AGREE |
| CONTGY | contingency coefficient | ALL or CHISQ |
| CRAMV | Cramer s V | ALL or CHISQ |
| EQKAP | test for equal elementary kappas | AGREE |
| EQWKP | test for equal weighted kappas | Hold |
| FISHER Exact | Fisher s exact test | ALL or CHISQ [] |
| GAMMA | gamma | ALL or MEASURES |
| JT | Jonckheere-Terpstra test | JT |
| KAPPA | simple kappa coefficient | AGREE |
| KENTB | Kendall s tau- b | ALL or MEASURES |
| LAMCR | lambda disproportionate ( C R ) | ALL or MEASURES |
| LAMDAS | lambda symmetric | ALL or MEASURES |
| LAMRC | lambda disproportionate ( R C ) | ALL or MEASURES |
| LGOR | adjusted logit odds ratio | ALL or CMH or CMH1 or CMH2 |
| LGRRC1 | adapted column 1 logit relative risk | ALL or CMH or CMH1 or CMH2 |
| LGRRC2 | adjusted column two logit relative risk | ALL or CMH or CMH1 or CMH2 |
| LRCHI | likelihood-ratio chi-square | ALL or CHISQ |
| MCNEM | McNemar south test | Concur |
| MEASURES | gamma, Kendall s tau- b , Stuart s tau- c , Somers D ( CR ), Somers D ( RC ), Pearson correlation coefficient, Spearman correlation coefficient, lambda asymmetric ( CR ), lambda disproportionate ( RC ), lambda symmetric, uncertainty coefficient ( CR ), uncertainty coefficient ( R C ), and symmetric uncertainty coefficient; for ii — 2 tables, odds ratio and relative risks | ALL or MEASURES |
| MHCHI | Mantel-Haenszel chi-foursquare | ALL or CHISQ |
| MHOR | adapted Mantel-Haenszel odds ratio | ALL or CMH or CMH1 or CMH2 |
| MHRRC1 | adjusted cavalcade 1 Mantel-Haenszel relative risk | ALL or CMH or CMH1 or CMH2 |
| MHRRC2 | adjusted cavalcade two Mantel-Haenszel relative risk | ALL or CMH or CMH1 or CMH2 |
| Due north | number of nonmissing subjects for the stratum | |
| NMISS | number of missing subjects for the stratum | |
| OR | odds ratio | ALL or MEASURES or RELRISK |
| PCHI | chi-foursquare goodness-of-fit test for one-fashion tables; for ii-style tables, Pearson chi-square | ALL or CHISQ |
| PCORR | Pearson correlation coefficient | ALL or MEASURES |
| PHI | phi coefficient | ALL or CHISQ |
| PLCORR | polychoric correlation coefficient | PLCORR |
| RDIF1 | column 1 hazard difference (row 1 - row 2) | RISKDIFF |
| RDIF2 | column 2 take chances difference (row 1 - row 2) | RISKDIFF |
| RELRISK | odds ratio and relative risks for 2 — two tables | ALL or MEASURES or RELRISK |
| RISKDIFF | risks and adventure differences | RISKDIFF |
| RISKDIFF1 | column 1 risks and risk difference | RISKDIFF |
| RISKDIFF2 | column 2 risks and risk difference | RISKDIFF |
| RRC1 | column 1 relative risk | ALL or MEASURES or RELRISK |
| RRC2 | cavalcade ii relative take a chance | ALL or MEASURES or RELRISK |
| RSK1 | column one risk (overall) | RISKDIFF |
| RSK11 | column i risk, for row 1 | RISKDIFF |
| RSK12 | cavalcade two take a chance, for row 1 | RISKDIFF |
| RSK2 | column 2 risk (overall) | RISKDIFF |
| RSK21 | column 1 take a chance, for row 2 | RISKDIFF |
| RSK22 | column 2 risk, for row two | RISKDIFF |
| SCORR | Spearman correlation coefficient | ALL or MEASURES |
| SMDCR | Somers D ( CR ) | ALL or MEASURES |
| SMDRC | Somers D ( RC ) | ALL or MEASURES |
| STUTC | Stuart s tau- c | ALL or MEASURES |
| TREND | Cochran-Armitage test for trend | TREND |
| TSYMM | Bowker s test of symmetry | Concord |
| U | symmetric incertitude coefficient | ALL or MEASURES |
| UCR | dubiousness coefficient ( CR ) | ALL or MEASURES |
| URC | dubiety coefficient ( RC ) | ALL or MEASURES |
| WTKAP | weighted kappa coefficient | Concur |
Using the TABLES Statement with the OUTPUT Argument
In lodge to specify that the OUTPUT data set contain a item statistic, you must have PROC FREQ compute the statistic by using the respective option in the TABLES argument or the Exact statement. For example, you cannot specify the option PCHI (Pearson chi-square) in the OUTPUT statement without also specifying a TABLES statement selection or an Verbal argument pick to compute the Pearson chi-foursquare. The TABLES statement selection ALL or CHISQ computes the Pearson chi-square. Additionally, if you have only one TABLES statement, the EXACT argument option CHISQ or PCHI computes the Pearson chi-square.
TABLES Argument
-
TABLES requests < / options > ;
The TABLES statement requests one-style to n -way frequency and crosstabulation tables and statistics for those tables.
If you omit the TABLES statement, PROC FREQ generates 1-way frequency tables for all data set variables that are not listed in the other statements.
The post-obit statement is required in the TABLES statement.
requests
-
specify the frequency and crosstabulation tables to produce. A asking is composed of i variable proper noun or several variable names separated by asterisks . To asking a one-way frequency table, utilise a single variable. To asking a ii-way crosstabulation table, use an asterisk between 2 variables. To request a multiway table (an northward -way table, where northward >2), separate the desired variables with asterisks. The unique values of these variables form the rows, columns , and strata of the table.
For two-mode to multiway tables, the values of the final variable form the crosstabulation table columns, while the values of the next-to-last variable form the rows. Each level (or combination of levels) of the other variables forms one stratum. PROC FREQ produces a separate crosstabulation tabular array for each stratum. For example, a specification of A*B*C*D in a TABLES statement produces k tables, where k is the number of dissimilar combinations of values for A and B . Each table lists the values for C down the side and the values for D across the top.
You can use multiple TABLES statements in the PROC FREQ step. PROC FREQ builds all the table requests in one pass of the data, so that in that location is essentially no loss of efficiency. Yous can as well specify whatever number of table requests in a unmarried TABLES statement. To specify multiple table requests quickly, use a grouping syntax by placing parentheses around several variables and joining other variables or variable combinations. For example, the following statements illustrate group syntax.
Table 2.8: Grouping Syntax Request
Equivalent to
tables A*(B C) ;
tables A*B A*C ;
tables (A B)*(C D) ;
tables A*C B*C A*D B*D ;
tables (A B C)*D ;
tables A*D B*D C*D ;
tables A " " C ;
tables A B C ;
tables (A " " C)*D ;
tables A*D B*D C*D ;
Without Options
If you request a one-way frequency table for a variable without specifying options, PROC FREQ produces frequencies, cumulative frequencies, percentages of the total frequency, and cumulative percentages for each value of the variable. If you request a two-way or an due north -way crosstabulation tabular array without specifying options, PROC FREQ produces crosstabulation tables that include cell frequencies, cell percentages of the full frequency, cell percentages of row frequencies, and cell percentages of column frequencies. The procedure excludes observations with missing values from the tabular array only displays the total frequency of missing observations below each tabular array.
Options
The following table lists the options available with the TABLES statement. Descriptions follow in alphabetical order.
| Option | Description |
|---|---|
| Control Statistical Assay | |
| AGREE | requests tests and measures of classification agreement |
| ALL | requests tests and measures of clan produced past CHISQ, MEASURES, and CMH |
| ALPHA= | sets the confidence level for confidence limits |
| BDT | requests Tarone s adjustment for the Breslow-Mean solar day test |
| BINOMIAL | requests binomial proportion, conviction limits and examination for ane-fashion tables |
| BINOMIALC | requests BINOMIAL statistics with a continuity correction |
| CHISQ | requests chi-foursquare tests and measures of clan based on chi-foursquare |
| CL | requests confidence limits for the MEASURES statistics |
| CMH | requests all Cochran-Mantel-Haenszel statistics |
| CMH1 | requests the CMH correlation statistic, and adapted relative risks and odds ratios |
| CMH2 | requests CMH correlation and row mean scores (ANOVA) statistics, and adjusted relative risks and odds ratios |
| CONVERGE= | specifies convergence criterion to compute polychoric correlation |
| FISHER | requests Fisher southward exact test for tables larger than 2 — 2 |
| JT | requests Jonckheere-Terpstra exam |
| MAXITER= | specifies maximum number of iterations to compute polychoric correlation |
| MEASURES | requests measures of association and their asymptotic standard errors |
| MISSING | treats missing values as nonmissing |
| PLCORR | requests polychoric correlation |
| RELRISK | requests relative take a chance measures for 2 — 2 tables |
| RISKDIFF | requests risks and take chances differences for ii — 2 tables |
| RISKDIFFC | requests RISKDIFF statistics with a continuity correction |
| SCORES= | specifies the blazon of row and column scores |
| TESTF= | specifies expected frequencies for a one-way table chi-square test |
| TESTP= | specifies expected proportions for a one-way table chi-square test |
| Tendency | requests Cochran-Armitage test for trend |
| Control Additional Table Information | |
| CELLCHI2 | displays each cell s contribution to the total Pearson chi-square statistic |
| CUMCOL | displays the cumulative column percentage in each cell |
| DEVIATION | displays the deviation of the jail cell frequency from the expected value for each cell |
| EXPECTED | displays the expected jail cell frequency for each cell |
| MISSPRINT | displays missing value frequencies |
| Sparse | lists all possible combinations of variable levels fifty-fifty when a combination does not occur |
| TOTPCT | displays percentage of total frequency on n -style tables when n > two |
| Command Displayed Output | |
| CONTENTS= | specifies the HTML contents link for crosstabulation tables |
| CROSSLIST | displays crosstabulation tables in ODS column format |
| FORMAT= | formats the frequencies in crosstabulation tables |
| LIST | displays two-mode to northward -fashion tables in list format |
| NOCOL | suppresses brandish of the column percentage for each cell |
| NOCUM | suppresses display of cumulative frequencies and cumulative percentages in ane-way frequency tables and in listing format |
| NOFREQ | suppresses brandish of the frequency count for each cell |
| NOPERCENT | suppresses display of the per centum, row percentage, and column percentage in crosstabulation tables, or percentages and cumulative percentages in one-way frequency tables and in list format |
| NOPRINT | suppresses display of tables but displays statistics |
| NOROW | suppresses brandish of the row percentage for each cell |
| NOSPARSE | suppresses zero cell frequencies in the list brandish and in the OUT= data set when ZEROS is specified |
| NOWARN | suppresses log alarm message for the chi-square test |
| PRINTKWT | displays kappa coefficient weights |
| SCOROUT | displays the row and the cavalcade scores |
| Create an Output Data Set | |
| OUT= | specifies an output data set to contain variable values and frequency counts |
| OUTCUM | includes the cumulative frequency and cumulative per centum in the output information set for one-way tables |
| OUTEXPECT | includes the expected frequency of each cell in the output information set |
| OUTPCT | includes the percent of column frequency, row frequency, and ii-way table frequency in the output data set |
You tin can specify the following options in a TABLES argument.
AGREE < (WT=FC) >
-
requests tests and measures of nomenclature agreement for foursquare tables. The Agree selection provides McNemar southward examination for ii — 2 tables and Bowker s test of symmetry for tables with more than 2 response categories. The AGREE option also produces the simple kappa coefficient, the weighted kappa coefficient, the asymptotic standard errors for the simple and weighted kappas, and the respective confidence limits. When there are multiple strata, the AGREE option provides overall simple and weighted kappas as well as tests for equal kappas among strata. When in that location are multiple strata and two response categories, PROC FREQ computes Cochran due south Q test. For more than data, run across the section Tests and Measures of Agreement on page 127.
The (WT=FC) specification requests that PROC FREQ employ Fleiss-Cohen weights to compute the weighted kappa coefficient. By default, PROC FREQ uses Cicchetti-Allison weights. Encounter the section Weighted Kappa Coefficient on page 130 for more data. You tin specify the PRINTKWT selection to display the kappa coefficient weights.
Agree statistics are computed only for foursquare tables, where the number of rows equals the number of columns. If your table is non foursquare due to observations with zilch weights, you can use the ZEROS option in the WEIGHT statement to include these observations. For more details, meet the section Tables with Zero Rows and Columns on page 133.
ALL
-
requests all of the tests and measures that are computed by the CHISQ, MEASURES, and CMH options. The number of CMH statistics computed can be controlled by the CMH1 and CMH2 options.
ALPHA= ±
-
specifies the level of confidence limits. The value of the ALPHA= pick must be betwixt 0 and 1, and the default is 0.05. A conviction level of ± produces 100(ane ˆ' ± )% confidence limits. The default of ALPHA=0.05 produces 95% confidence limits.
ALPHA= applies to confidence limits requested by TABLES statement options. In that location is a carve up Alpha= choice in the Exact statement that sets the level of confidence limits for Monte Carlo estimates of exact p -values, which are requested in the EXACT argument.
BDT
-
requests Tarone s aligning in the Breslow-Day exam for homogeneity of odds ratios. (Y'all must specify the CMH option to compute the Breslow-Twenty-four hours test.) Meet the section Breslow-Day Test for Homogeneity of the Odds Ratios on page 142 for more information.
BINOMIAL < (P= value ) (LEVEL= level-number level-value ) >
-
requests the binomial proportion for one-way tables. The BINOMIAL choice also provides the asymptotic standard error, asymptotic and exact confidence intervals, and the asymptotic test for the binomial proportion. To request an verbal exam for the binomial proportion, employ the BINOMIAL pick in the Verbal statement.
To specify the null hypothesis proportion for the exam, utilise P=. If yous omit P= value , PROC FREQ uses 0.5 every bit the default for the test. By default, BINOMIAL computes the proportion of observations for the starting time variable level that appears in the output. To specify a unlike level, utilise LEVEL= level-number or LEVEL= level-value , where level-number is the variable level s number or order in the output, and level-value is the formatted value of the variable level.
To include a continuity correction in the asymptotic conviction interval and test, use the BINOMIALC selection instead of the BINOMIAL option.
See the department Binomial Proportion on page 118 for more information.
BINOMIALC < (P= value ) (LEVEL= level-number level-value ) >
-
requests the BINOMIAL option statistics for one-mode tables, and includes a continuity correction in the asymptotic confidence interval and the asymptotic exam. The BINOMIAL option statistics include the binomial proportion, the asymptotic standard fault, asymptotic and verbal confidence intervals, and the asymptotic test for the binomial proportion. To asking an exact test for the binomial proportion, use the BINOMIAL option in the EXACT argument.
To specify the null hypothesis proportion for the test, employ P=. If you omit P= value , PROC FREQ uses 0.five as the default for the test. By default BINOMIALC computes the proportion of observations for the offset variable level that appears in the output. To specify a different level, employ LEVEL= level-number or LEVEL= level-value , where level-number is the variable level s number or guild in the output, and level-value is the formatted value of the variable level.
Encounter the section Binomial Proportion on folio 118 for more information.
CELLCHI2
-
displays each crosstabulation table cell s contribution to the total Pearson chi-square statistic, which is computed as
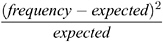
The CELLCHI2 option has no effect for one-way tables or for tables that are displayed with the LIST pick.
CHISQ
-
requests chi-foursquare tests of homogeneity or independence and measures of association based on chi-foursquare. The tests include the Pearson chi-square, likelihood-ratio chi-square, and Mantel-Haenszel chi-square. The measures include the phi coefficient, the contingency coefficient, and Cramer s Five . For 2 — 2 tables, the CHISQ option includes Fisher southward exact examination and the continuity-adjusted chi-square. For one-way tables, the CHISQ option requests a chi-square goodness-of-fit examination for equal proportions. If you specify the cipher hypothesis proportions with the TESTP= option, then PROC FREQ computes a chi-square goodness-of-fit test for the specified proportions. If y'all specify null hypothesis frequencies with the TESTF= pick, PROC FREQ computes a chi-square goodness-of-fit test for the specified frequencies. Encounter the section Chi-Square Tests and Statistics on folio 103 for more than information.
CL
-
requests confidence limits for the MEASURES statistics. If you omit the MEASURES choice, the CL option invokes MEASURES. The FREQ procedure determines the confidence coefficient using the ALPHA= selection, which, by default, equals 0.05 and produces 95% confidence limits.
For more information, meet the section Conviction Limits on page 109.
CMH
-
requests Cochran-Mantel-Haenszel statistics, which test for association betwixt the row and column variables after adjusting for the remaining variables in a multiway table. In addition, for 2 — 2 tables, PROC FREQ computes the adapted Mantel-Haenszel and logit estimates of the odds ratios and relative risks and the corresponding confidence limits. For the stratified 2 — two case, PROC FREQ computes the Breslow-Day examination for homogeneity of odds ratios. (To request Tarone s adjustment for the Breslow-Day test, apply the BDT option.) The CMH1 and CMH2 options command the number of CMH statistics that PROC FREQ computes. For more information, meet the section Cochran-Mantel-Haenszel Statistics on folio 134.
CMH1
-
requests the Cochran-Mantel-Haenszel correlation statistic and, for 2 — 2 tables, the adjusted Mantel-Haenszel and logit estimates of the odds ratios and relative risks and the corresponding conviction limits. For the stratified two — 2 case, PROC FREQ computes the Breslow-Day test for homogeneity of odds ratios. Except for 2 — 2 tables, the CMH1 option requires less memory than the CMH selection, which can require an enormous corporeality for large tables.
CMH2
-
requests the Cochran-Mantel-Haenszel correlation statistic, row hateful scores (ANOVA) statistic, and, for 2 — 2 tables, the adjusted Mantel-Haenszel and logit estimates of the odds ratios and relative risks and the corresponding confidence limits. For the stratified 2 — 2 case, PROC FREQ computes the Breslow-Day test for homogeneity of odds ratios. Except for tables with two columns, the CMH2 selection requires less memory than the CMH selection, which tin can require an enormous amount for big tables.
CONTENTS= link-text
-
specifies the text for the HTML contents file links to crosstabulation tables. For data on HTML output, refer to the SAS Output Commitment Arrangement User s Guide . The CONTENTS= choice affects just the HTML contents file, and not the HTML body file.
If you omit the CONTENTS= option, by default, the HTML link text for crosstabulation tables is Cross-Tabular Freq Table.
Note that links to all crosstabulation tables produced by a single TABLES argument utilize the same text. To specify different text for different crosstabulation table links, asking the tables in separate TABLES statements and use the CONTENTS= option in each TABLES statement.
The CONTENTS= pick affects only links to crosstabulation tables. It does not bear on links to other PROC FREQ tables. To specify link text for any other PROC FREQ table, you tin use PROC TEMPLATE to create a customized table definition. The CONTENTS "LABEL attribute in the DEFINE Table statement of PROC TEMPLATE specifies the contents file link for the tabular array. For detailed information, refer to the affiliate titled The TEMPLATE Process in the SAS Output Delivery System User s Guide .
CONVERGE= value
-
specifies the convergence criterion for calculating the polychoric correlation when you specify the PLCORR pick. The value of the CONVERGE= option must be a positive number; by default, CONVERGE=0.0001. Iterative computation of the polychoric correlation stops when the convergence mensurate falls beneath the value of the CONVERGE= choice or when the number of iterations exceeds the value specified in the MAXITER= option, whichever happens first.
Meet the section Polychoric Correlation on page 116 for more information.
CROSSLIST
-
displays crosstabulation tables in ODS column format, instead of the default crosstabulation jail cell format. In a CROSSLIST table display, the rows correspond to the crosstabulation table cells, and the columns correspond to descriptive statistics such as Frequency, Percent, and so on. See the department Multiway Tables on page 152 for details on the contents of the CROSSLIST table.
The CROSSLIST table displays the same information as the default crosstabulation table, just uses an ODS column format instead of the table cell format. Unlike the default crosstabulation table, the CROSSLIST table has a table definition that you tin customize with PROC TEMPLATE. For more than information, refer to the chapter titled The TEMPLATE Procedure in the SAS Output Commitment Organization User due south Guide .
You can control the contents of a CROSSLIST table with the same options available for the default crosstabulation table. These include the NOFREQ, NOPERCENT, NOROW, and NOCOL options. You can request additional information in a CROSSLIST table with the CELLCHI2, Difference, EXPECTED, MISSPRINT, and TOTPCT options.
The FORMAT= option and the CUMCOL option take no effect for CROSSLIST tables. You cannot specify both the List option and the CROSSLIST selection in the same TABLES statement.
You can use the NOSPARSE option to suppress brandish of variable levels with goose egg frequency in CROSSLIST tables. By default for CROSSLIST tables, PROC FREQ displays all levels of the column variable within each level of the row variable, including whatsoever column variable levels with zilch frequency for that row. And for multiway tables displayed with the CROSSLIST option, the process displays all levels of the row variable for each stratum of the table by default, including any row variable levels with zip frequency for the stratum.
CUMCOL
-
displays the cumulative column percentages in the cells of the crosstabulation table.
Difference
-
displays the deviation of the prison cell frequency from the expected frequency for each cell of the crosstabulation table. The Departure option is valid for contingency tables merely has no event on tables produced with the List pick.
EXPECTED
-
displays the expected tabular array jail cell frequencies under the hypothesis of independence (or homogeneity). The EXPECTED pick is valid for crosstabulation tables but has no consequence on tables produced with the List option.
FISHER EXACT
-
requests Fisher south exact test for tables that are larger than 2 — two. This test is too known as the Freeman-Halton test. For more than information, see the department Fisher due south Verbal Examination on folio 106 and the Exact Statement section on page 77.
If you omit the CHISQ option in the TABLES statement, the FISHER choice invokes CHISQ. You tin besides asking Fisher southward exact exam by specifying the FISHER option in the Verbal statement.
Caution: For tables with many rows or columns or with big total frequency, PROC FREQ may require a large amount of time or retention to compute exact p -values. Come across the section Computational Resources on page 145 for more data.
FORMAT= format-name
-
specifies a format for the following crosstabulation table cell values: frequency, expected frequency, and departure. PROC FREQ also uses this format to brandish the total row and column frequencies for crosstabulation tables.
You can specify any standard SAS numeric format or a numeric format defined with the FORMAT procedure. The format length must non exceed 24. If yous omit FORMAT=, by default, PROC FREQ uses the BEST6. format to display frequencies less than 1E6, and the BEST7. format otherwise.
To change formats for all other FREQ tables, you tin use PROC TEMPLATE. For data on this process, refer to the chapter titled The TEMPLATE Process in the SAS Output Commitment System User due south Guide .
JT
-
performs the Jonckheere-Terpstra test. For more information, see the section Jonckheere-Terpstra Test on page 125.
List
-
displays two-way to n -way tables in a list format rather than as crosstabulation tables. PROC FREQ ignores the LIST option when you request statistical tests or measures of association.
MAXITER= number
-
specifies the maximum number of iterations for computing the polychoric correlation when you specify the PLCORR option. The value of the MAXITER= selection must be a positive integer; by default, MAXITER=20. Iterative computation of the polychoric correlation stops when the number of iterations exceeds the value of the MAXITER= selection, or when the convergence measure falls beneath the value of the CONVERGE= selection, whichever happens offset. For more information see the section Polychoric Correlation on page 116.
MEASURES
-
requests several measures of association and their asymptotic standard errors (ASE). The measures include gamma, Kendall s tau- b , Stuart s tau- c , Somers D ( C R ), Somers D ( R C ), the Pearson and Spearman correlation coefficients, lambda (symmetric and asymmetric), uncertainty coefficients (symmetric and asymmetric). To request confidence limits for these measures of association, you can specify the CL pick.
For ii — 2 tables, the MEASURES option as well provides the odds ratio, column ane relative risk, column two relative gamble, and the corresponding conviction limits. Alternatively, you can obtain the odds ratio and relative risks, without the other measures of association, past specifying the RELRISK option.
For more data, run across the section Measures of Association on page 108.
MISSING
-
treats missing values every bit nonmissing and includes them in calculations of percentages and other statistics.
For more data, see the section Missing Values on page 100.
MISSPRINT
-
displays missing value frequencies for all tables, even though PROC FREQ does non use the frequencies in the calculation of statistics. For more information, come across the department Missing Values on page 100.
NOCOL
-
suppresses the display of column percentages in cells of the crosstabulation table.
NOCUM
-
suppresses the display of cumulative frequencies and cumulative percentages for one-style frequency tables and for crosstabulation tables in list format.
NOFREQ
-
suppresses the display of jail cell frequencies for crosstabulation tables. This too suppresses frequencies for row totals.
NOPERCENT
-
suppresses the brandish of cell percentages, row total percentages, and column full percentages for crosstabulation tables. For one-mode frequency tables and crosstabulation tables in list format, the NOPERCENT pick suppresses the display of percentages and cumulative percentages.
NOPRINT
-
suppresses the display of frequency and crosstabulation tables merely displays all requested tests and statistics. Utilize the NOPRINT pick in the PROC FREQ statement to suppress the brandish of all tables.
NOROW
-
suppresses the brandish of row percentages in cells of the crosstabulation table.
NOSPARSE
-
requests that PROC FREQ not invoke the SPARSE option when you specify the ZEROS choice in the WEIGHT statement. The NOSPARSE option suppresses the brandish of cells with a zero frequency count in the list output, and it besides omits them from the OUT= data set. By default, the ZEROS choice invokes the Sparse choice, which displays table cells with a nothing frequency count in the List output and includes them in the OUT= data set. For more than information, see the description of the ZEROS option.
For CROSSLIST tables, the NOSPARSE selection suppresses display of variable levels with zero frequency. By default for CROSSLIST tables, PROC FREQ displays all levels of the column variable inside each level of the row variable, including any cavalcade variable levels with zero frequency for that row. And for multiway tables displayed with the CROSSLIST selection, the procedure displays all levels of the row variable for each stratum of the table by default, including any row variable levels with zero frequency for the stratum.
NOWARN
-
suppresses the log warning bulletin that the asymptotic chi-square examination may not be valid. By default, PROC FREQ displays this log message when more than than 20 percent of the tabular array cells have expected frequencies less than five.
OUT= SAS-data-set
-
names the output data set that contains variable values and frequency counts. The variable COUNT contains the frequencies and the variable Percent contains the percentages. If more than than ane table request appears in the TABLES statement, the contents of the information set correspond to the last tabular array request in the TABLES statement. For more data, see the department Output Data Sets on page 148 and see the following descriptions for the options OUTCUM, OUTEXPECT, and OUTPCT.
OUTCUM
-
includes the cumulative frequency and the cumulative pct for one-way tables in the output data set when you specify the OUT= option in the TABLES statement. The variable CUM "FREQ contains the cumulative frequency for each level of the analysis variable, and the variable CUM "PCT contains the cumulative percentage for each level. The OUTCUM option has no effect for two-fashion or multiway tables.
For more information, meet the section Output Data Sets on folio 148.
OUTEXPECT
-
includes the expected frequency in the output data ready for crosstabulation tables when you specify the OUT= selection in the TABLES statement. The variable EXPECTED contains the expected frequency for each table cell. The EXPECTED choice is valid for two-way or multiway tables, and has no consequence for i-way tables.
For more information, run across the section Output Data Sets on page 148.
OUTPCT
-
includes the following additional variables in the output data prepare when you specify the OUT= selection in the TABLES statement for crosstabulation tables:
PCT "COL
the percent of cavalcade frequency
PCT "ROW
the percentage of row frequency
Percentage "TABL
the percentage of stratum frequency, for north -way tables where northward > 2
The OUTPCT option is valid for two-way or multiway tables, and has no result for one-manner tables.
For more than information, see the section Output Data Sets on page 148.
PLCORR
-
requests the polychoric correlation coefficient. For 2 — 2 tables, this statistic is more commonly known as the tetrachoric correlation coefficient, and it is labeled as such in the displayed output. If you omit the MEASURES option, the PLCORR choice invokes MEASURES. For more data, come across the section Polychoric Correlation on page 116 and the descriptions for the CONVERGE= and MAXITER= options in this list.
PRINTKWT
-
displays the weights PROC FREQ uses to compute the weighted kappa coefficient. You must also specify the AGREE selection, which requests the weighted kappa coefficient. Yous can specify (WT=FC) with the AGREE option to request Fleiss-Cohen weights. By default, PROC FREQ uses Cicchetti-Allison weights.
-
Run across the section Weighted Kappa Coefficient on folio 130 for more information.
RELRISK
-
requests relative risk measures and their confidence limits for 2 — 2 tables. These measures include the odds ratio and the column 1 and 2 relative risks. For more information, run across the section Odds Ratio and Relative Risks for ii x ii Tables on page 122. You can also obtain the RELRISK measures by specifying the MEASURES option, which produces other measures of association in add-on to the relative risks.
RISKDIFF
-
requests column 1 and 2 risks (or binomial proportions), risk differences, and their conviction limits for ii — 2 tables. See the section Risks and Risk Differences on page 120 for more information.
RISKDIFFC
-
requests the RISKDIFF option statistics for 2 — 2 tables, and includes a continuity correction in the asymptotic confidence limits. The RISKDIFF option statistics include the column ane and ii risks (or binomial proportions), risk differences, and their confidence limits. See the section Risks and Risk Differences on page 120 for more than information.
SCORES= type
-
specifies the type of row and column scores that PROC FREQ uses with the Mantel-Haenszel chi-square, Pearson correlation, Cochran-Armitage test for tendency, weighted kappa coefficient, and Cochran-Mantel-Haenszel statistics, where type is one of the following (the default is SCORE=TABLE):
-
MODRIDIT
-
RANK
-
RIDIT
-
Table
-
-
By default, the row or column scores are the integers 1,ii,... for character variables and the actual variable values for numeric variables. Using other types of scores yields nonparametric analyses. For more data, encounter the section Scores on page 102.
To display the row and cavalcade scores, you tin can utilize the SCOROUT option.
SCOROUT
-
displays the row and the column scores. Yous specify the score blazon with the SCORES= option. PROC FREQ uses the scores when it calculates the Mantel-Haenszel chi-square, Pearson correlation, Cochran-Armitage examination for trend, weighted kappa coefficient, or Cochran-Mantel-Haenszel statistics. The SCOROUT choice displays the row and column scores just when statistics are computed for two-way tables. To store the scores in an output data set, use the Output Delivery Organization.
For more than information, run across the section Scores on page 102.
SPARSE
-
lists all possible combinations of the variable values for an n -way table when northward > 1, even if a combination does not occur in the data. The Sparse option applies merely to crosstabulation tables displayed in list format and to the OUT= output information set. Otherwise, if yous do not use the LIST choice or the OUT= option, the Thin choice has no effect.
When yous specify the SPARSE and LIST options, PROC FREQ displays all combinations of variable variables in the table listing, including those values with a frequency count of zero. Past default, without the SPARSE option, PROC FREQ does not display aught-frequency values in listing output. When you employ the SPARSE and OUT= options, PROC FREQ includes empty crosstabulation tabular array cells in the output data gear up. By default, PROC FREQ does non include aught-frequency tabular array cells in the output data set.
For more data, see the department Missing Values on folio 100.
TESTF=( values )
-
specifies the null hypothesis frequencies for a one-mode chi-foursquare exam for specified frequencies. You can split values with blanks or commas. The sum of the frequency values must equal the total frequency for the one-manner table. The number of TESTF= values must equal the number of variable levels in the ane-way tabular array. List these values in the order in which the corresponding variable levels appear in the output. If you omit the CHISQ option, the TESTF= option invokes CHISQ.
For more than information, see the department Chi-Foursquare Test for One-Way Tables on folio 104.
TESTP=( values )
-
specifies the null hypothesis proportions for a one-way chi-foursquare test for specified proportions. You tin separate values with blanks or commas. Specify values in probability form as numbers between 0 and 1, where the proportions sum to 1. Or specify values in percentage form as numbers between 0 and 100, where the percentages sum to 100. The number of TESTP= values must equal the number of variable levels in the 1-way table. List these values in the order in which the corresponding variable levels announced in the output. If yous omit the CHISQ selection, the TESTP= choice invokes CHISQ.
For more data, see the section Chi-Square Examination for One-Way Tables on folio 104.
TOTPCT
-
displays the percentage of total frequency in crosstabulation tables, for north -style tables where north > two. This percentage is too available with the List option or as the Pct variable in the OUT= output data set.
Tendency
-
performs the Cochran-Armitage test for trend. The tabular array must exist 2 — C or R — 2. For more information, run into the section Cochran-Armitage Test for Trend on page 124.
TEST Statement
-
TEST options ;
The TEST statement requests asymptotic tests for the specified measures of association and measures of agreement. You must utilise a TABLES statement with the TEST statement.
options
-
specify the statistics for which to provide asymptotic tests. The available statistics are those measures of association and agreement listed in Table 2.10. The pick names are identical to those in the TABLES argument and the OUTPUT statement. You lot can asking all bachelor tests for groups of statistics by using group options MEASURES or AGREE. Or you tin request tests individually by using one of the options shown in Table 2.10.
Table 2.x: Test Statement Options and Required TABLES Statement Options Option
Asymptotic Tests Computed
Required TABLES Statement Option
AGREE
simple kappa coefficient and weighted kappa coefficient
AGREE
GAMMA
gamma
ALL or MEASURES
KAPPA
simple kappa coefficient
AGREE
KENTB
Kendall due south tau- b
ALL or MEASURES
MEASURES
gamma, Kendall south tau- b , Stuart s tau- c , Somers D ( C R ), Somers D ( R C ), the Pearson correlation, and the Spearman correlation
ALL or MEASURES
PCORR
Pearson correlation coefficient
ALL or MEASURES
SCORR
Spearman correlation coefficient
ALL or MEASURES
SMDCR
Somers D ( C R )
ALL or MEASURES
SMDRC
Somers D ( R C )
ALL or MEASURES
STUTC
Stuart s tau- c
ALL or MEASURES
WTKAP
weighted kappa coefficient
Hold
For each measure of clan or agreement that you specify, the TEST statement provides an asymptotic exam that the measure out equals zero. When you request an asymptotic test, PROC FREQ gives the asymptotic standard mistake nether the zip hypothesis, the examination statistic, and the p -values. Additionally, PROC FREQ reports the conviction limits for that mensurate. The Blastoff= option in the TABLES statement determines the confidence level, which, by default, equals 0.05 and provides 95% confidence limits. For more information, see the sections Asymptotic Tests on folio 109 and Confidence Limits on page 109, and see Statistical Computations starting time on page 102 for sections describing the private measures.
In addition to these asymptotic tests, exact tests for selected measures of association and agreement are available with the EXACT statement. Run into the section EXACT Statement on folio 77 for more information.
WEIGHT Argument
-
WEIGHT variable < / selection > ;
The WEIGHT argument specifies a numeric variable with a value that represents the frequency of the observation. The WEIGHT statement is near commonly used to input cell count information. See the Inputting Frequency Counts section on page 98 for more information. If y'all apply the WEIGHT statement, PROC FREQ assumes that an ascertainment represents n observations, where n is the value of variable . The value of the weight variable need not exist an integer. When a weight value is missing, PROC FREQ ignores the respective ascertainment. When a weight value is cipher, PROC FREQ ignores the corresponding observation unless you specify the ZEROS option, which includes observations with null weights. If a WEIGHT statement does non appear, each observation has a default weight of ane. The sum of the weight variable values represents the total number of observations.
If any value of the weight variable is negative, PROC FREQ displays the frequencies (as measured past the weighted values) but does non compute percentages and other statistics. If you create an output data ready using the OUT= option in the TABLES statement, PROC FREQ creates the PERCENT variable and assigns a missing value for each observation. PROC FREQ as well assigns missing values to the variables that the OUTEXPECT and OUTPCT options create. You cannot create an output information set using the OUTPUT statement since statistics are not computed when in that location are negative weights.
Option
ZEROS
-
includes observations with zero weight values. By default, PROC FREQ ignores observations with zero weights.
If you lot specify the ZEROS option, frequency and and crosstabulation tables display whatsoever levels corresponding to observations with zip weights. Without the ZEROS option, PROC FREQ does not process observations with zero weights, and and then does not display levels that contain only observations with zero weights.
With the ZEROS option, PROC FREQ includes levels with zero weights in the chi-foursquare goodness-of-fit exam for one-way tables. Also, PROC FREQ includes any levels with aught weights in binomial computations for ane-way tables. This enables computation of binomial estimates and tests when there are no observations with positive weights in the specified level.
For two-way tables, the ZEROS option enables computation of kappa statistics when at that place are levels containing no observations with positive weight. For more information, run across the section Tables with Zero Rows and Columns on page 133.
Note that even with the ZEROS selection, PROC FREQ does not compute the CHISQ or MEASURES statistics for two-style tables when the table has a zero row or cipher column, because virtually of these statistics are undefined in this example.
The ZEROS choice invokes the Sparse selection in the TABLES argument, which includes table cells with a aught frequency count in the list output and the OUT= data set. By default, without the SPARSE selection, PROC FREQ does not include nix frequency cells in the listing output or in the OUT= data set. If you specify the ZEROS choice in the WEIGHT statement but do not want the Sparse pick, you tin can specify the NOSPARSE selection in the TABLES statement.
Source: https://flylib.com/books/en/4.497.1.13/1/
0 Response to "Proc Freq Table Riskdiff How to Read"
Post a Comment